



将 OpenLibrary 和 Archive.org 文本下载为 PDF
Archive.org/OpenLibrary.org Flipbook 到 PDF 下载器允许您从 Archive.org 和 OpenLibrary.org 下载 Flipbook(图书预览或借用的电子书)作为 PDF。它会自动扫描所有可用页面,提取高质量图像(包括基于 blob 的预览),并将其编译成可下载的 PDF 文件,非常适合离线阅读或研究。
主要特点:
✔ 将书籍预览转换为 PDF – 适用于 Archive.org 和 OpenLibrary.org
✔ 支持基于 blob 的图像 – 即使页面使用 blob URL 也能提取页面
✔ 自动滚动页面 – 无需手动点击
✔ 删除重复项 – 确保干净、页面完美的输出
✔ 轻量且快速 – 针对流畅的性能进行了优化
✔ 设置 PDF 页面方向 - 纵向或横向
✔ 设置缩放模式 - 填充整个页面或适合比例
运作原理:
在 Archive.org 或 OpenLibrary.org 上打开图书预览
单击扩展图标
开始扫描 - 它将自动滚动并捕获所有页面
一键下载生成的 PDF。
免费版本的页面上将添加水印。
注意:为了获得最高质量,我们建议以“单页视图”打开书籍并以该模式开始扫描。这样捕获的图像将具有更高的分辨率。
为什么使用这个扩展?
保留图书预览以供离线访问
便于研究 – 将页面保存为单个 PDF
免费试用 - 功能齐全的演示版
清洁直接提取,透明安全延伸
Archive.org Flipbook to PDF Downloader插件谷歌浏览器安装教程
第一步:下载Archive.org Flipbook to PDF Downloader安装扩展
第二步:下载下来的扩展解压到你想放的文件夹里
比如我解压到extend文件夹

打开Chrome的扩展页面(chrome:// extensions /或按Chrome菜单图标>更多工具>扩展程序),右上角开发者模式,点击开启,蓝色为开启,灰色为关闭;
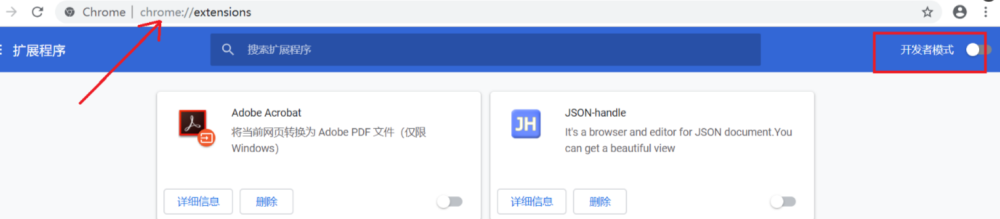
再次将crx文件拖放到扩展程序,页面左下角提示:“扩展功能、应用和主题背景可能会损害您的计算机。您确定要继续吗?”
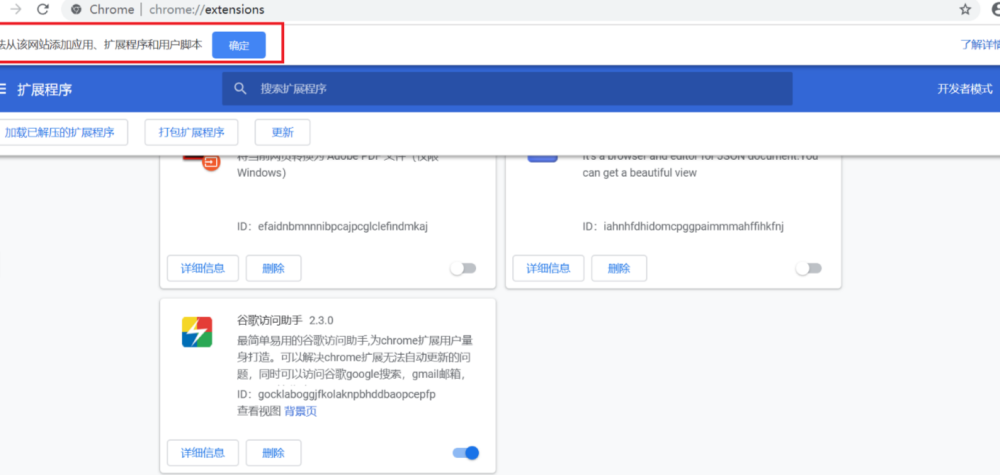
点击“继续”依然显示“无法从该网站添加应用、扩展程序和用户脚本”。尝试另一种办法方法。
第三步:把crx后缀改为zip,再进行解压
如果有些windows电脑系统查看不到文件扩展名,则可以通过以下设置:
找到文件夹顶部,点击查看

点击查看,找到隐藏已知文件扩展名,去掉前面的勾即可
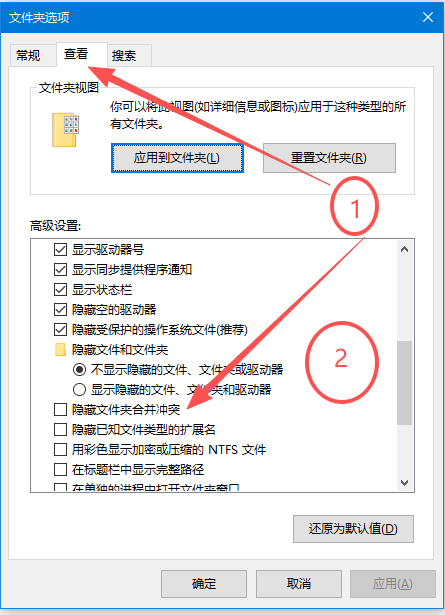
这样你就能看到解压好的扩展名:.crx
解压的扩展名为.crx
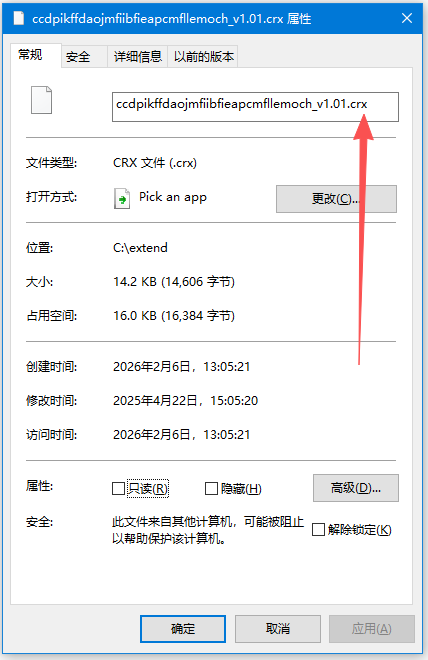
把.crx改为:zip
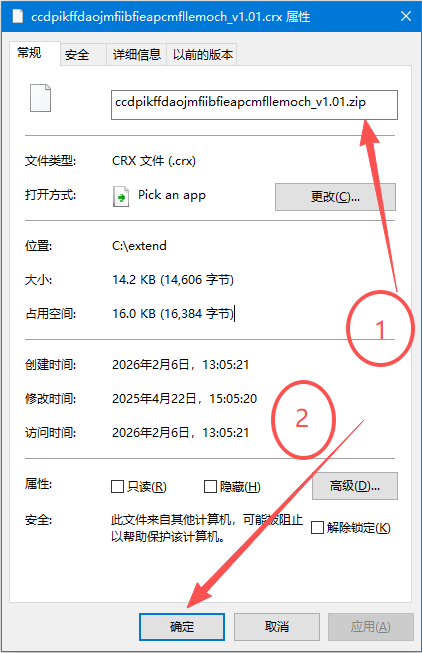
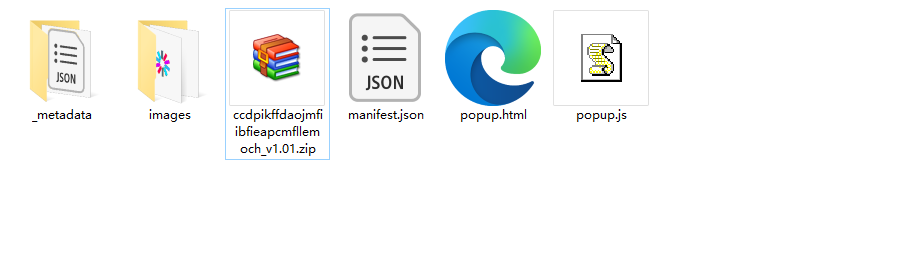
然后再用解压工具再解压一遍,即可得到扩展的全部文件
然后再谷歌浏览器插件页面选择:加载已解压的扩展程序
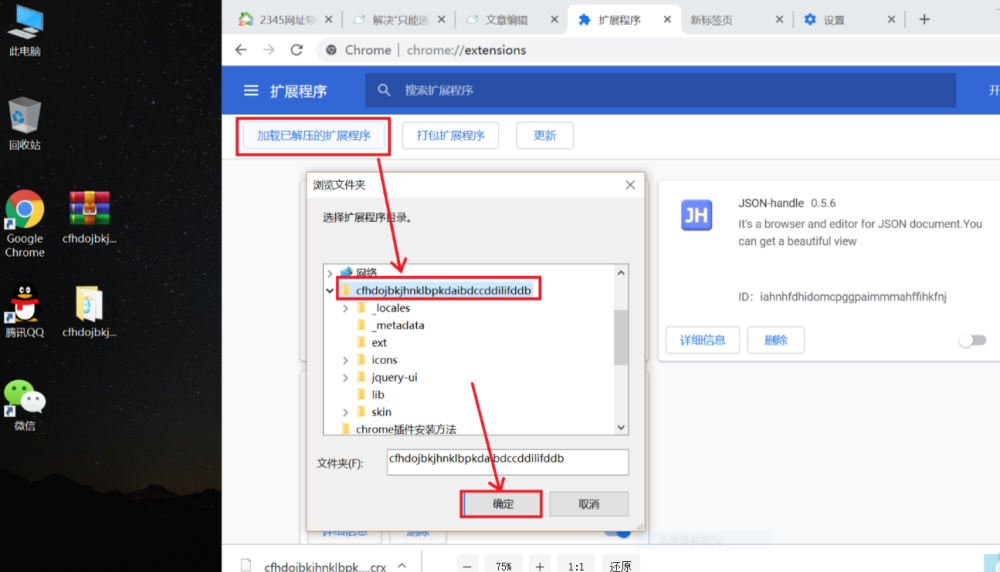
这样就安装成功了
友情提醒:
其他浏览器,包括qq浏览器,360浏览器,edge浏览器,猎豹浏览器,搜狗浏览器安装插件的方法都是类似的,以上内容大部分通用!















