




简单的无代码浏览器 RPA 工具,可轻松实现网页自动化、数据抓取、数据录入、数据采集,以及从网站导出数据到 Excel。
## 无代码网页自动化数据采集器
Tapicker 是一款强大的无代码浏览器 RPA 工具,专为网页自动化、数据采集和数据提取而设计。通过直观的可视化编辑器,您可以轻松实现数据录入、网页监控、图片下载、邮件提取等任务——无需编写代码。
Tapicker 帮助您简化重复性工作、抓取网站数据,并高效自动化工作流程。无论您是企业家、自由职业者还是商务人士,这款浏览器扩展都能通过简化复杂任务来提升您的工作效率。
## 主要功能:
• 无代码可视化自动化 – 拖放式界面,轻松创建工作流
• 灵活的数据采集 – 提取网页中的结构化数据,支持 iframe 和 Shadow DOM
• 智能表单自动化 – 自动填写表单、选择选项并动态提交
• 高级流程控制 – 支持循环、条件判断、分支和延迟执行
• 并行任务执行 – 可同时自动化多个页面和标签页
• 网页监控 – 跟踪网站更新并提取实时数据
• 智能导航 – 支持无限滚动、分页和随机访问
• 数据转换与导出 – 以 XLSX、CSV、JSON 和 XML 格式保存提取数据
• 自动化元素交互 – 模拟点击、悬停和页面导航,无需手动操作
• 批量图片下载 – 自动采集并保存网页上的图片
• 邮件提取 – 从网站提取电子邮件地址,用于潜在客户开发
## 应用场景:
• 通过构建测试流程自动化 UI 测试
• 抓取社交媒体数据,获取市场营销和商业洞察
• 从旧系统提取客户数据,实现数据录入自动化
• 监控竞争对手定价,抓取电商网站数据
• 从招聘网站收集简历,提高招聘效率
• 训练 AI 模型,采集大规模行业数据
• 提取邮件列表,用于商业推广
• 以及更多应用场景……
## 立即开始体验
从我们的免费公共自动化示例入手——只需复制并修改,即可快速了解 Tapicker 的工作原理。随时升级以解锁高级网页自动化功能。
探索 Tapicker 的无限可能,让数据提取、网页抓取和浏览器自动化变得轻而易举!
塔皮克 - 浏览器网页自动化数据采集器插件谷歌浏览器安装教程
第一步:下载塔皮克 - 浏览器网页自动化数据采集器安装扩展
第二步:下载下来的扩展解压到你想放的文件夹里
比如我解压到extend文件夹

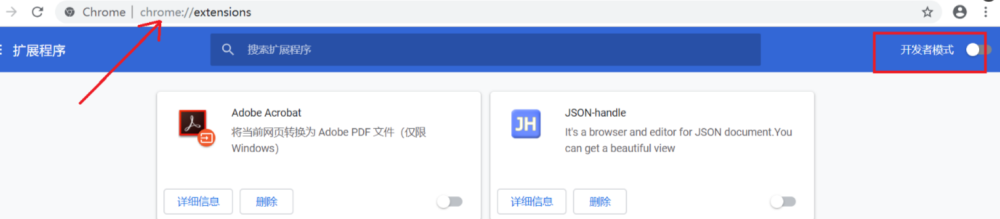
打开Chrome的扩展页面(chrome:// extensions /或按Chrome菜单图标>更多工具>扩展程序),右上角开发者模式,点击开启,蓝色为开启,灰色为关闭;
再次将crx文件拖放到扩展程序,页面左下角提示:“扩展功能、应用和主题背景可能会损害您的计算机。您确定要继续吗?”
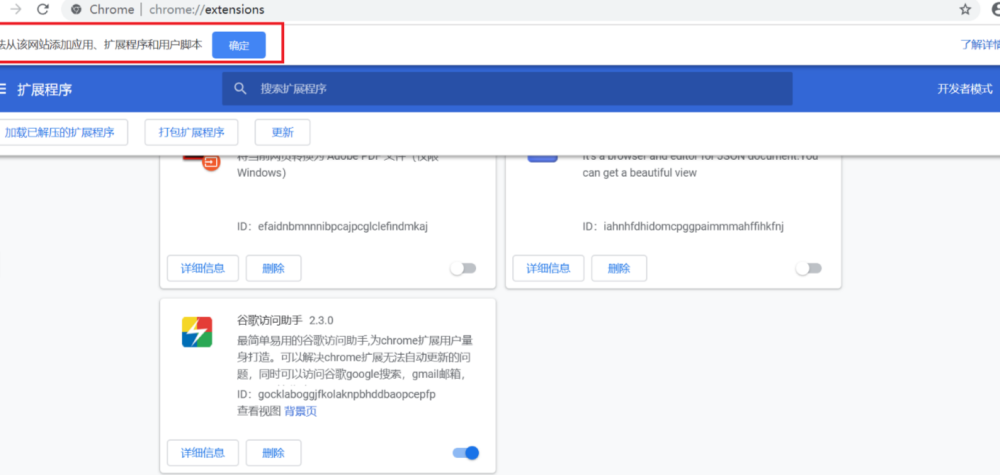
点击“继续”依然显示“无法从该网站添加应用、扩展程序和用户脚本”。尝试另一种办法方法。
第三步:把crx后缀改为zip,再进行解压
如果有些windows电脑系统查看不到文件扩展名,则可以通过以下设置:
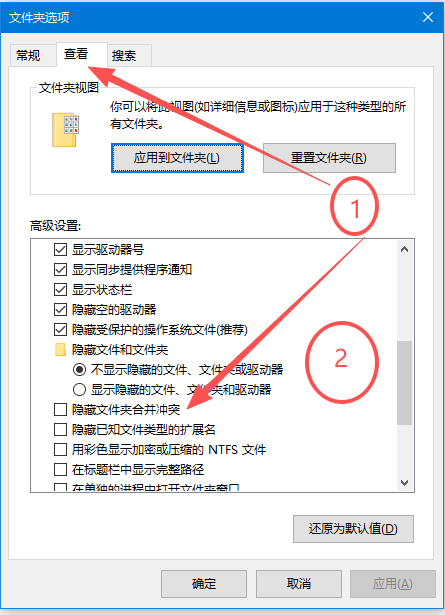
找到文件夹顶部,点击查看

点击查看,找到隐藏已知文件扩展名,去掉前面的勾即可
这样你就能看到解压好的扩展名:.crx
解压的扩展名为.crx
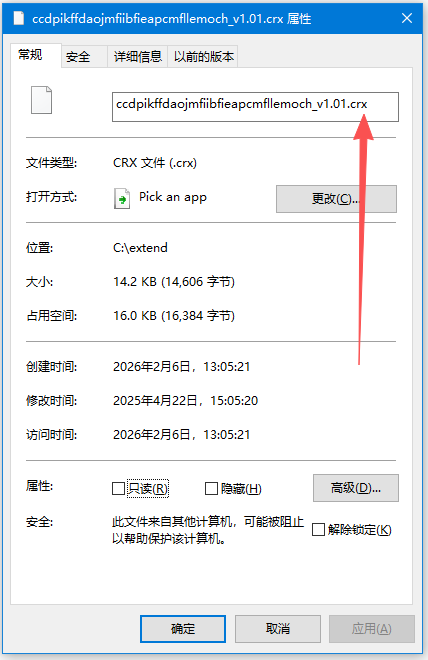
把.crx改为:zip
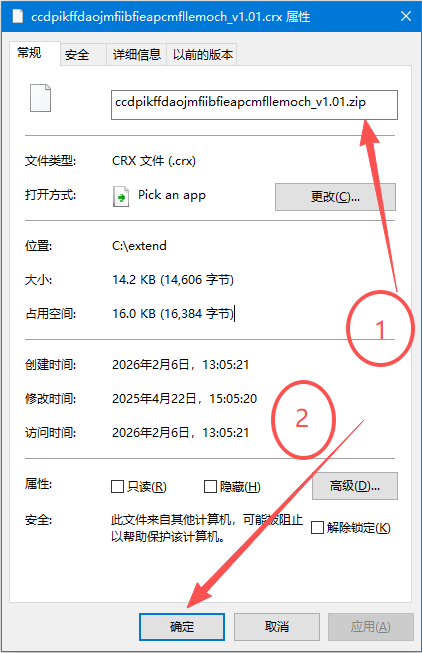
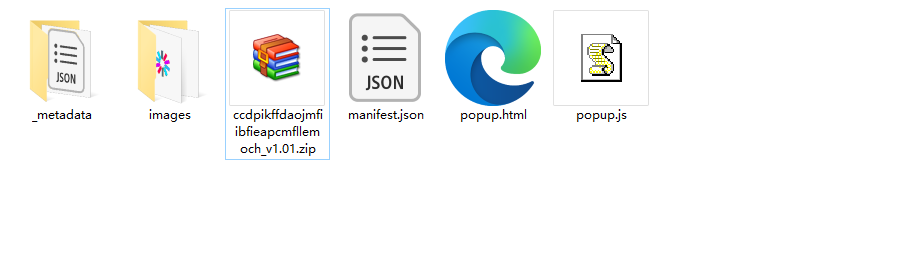
然后再用解压工具再解压一遍,即可得到扩展的全部文件
然后再谷歌浏览器插件页面选择:加载已解压的扩展程序
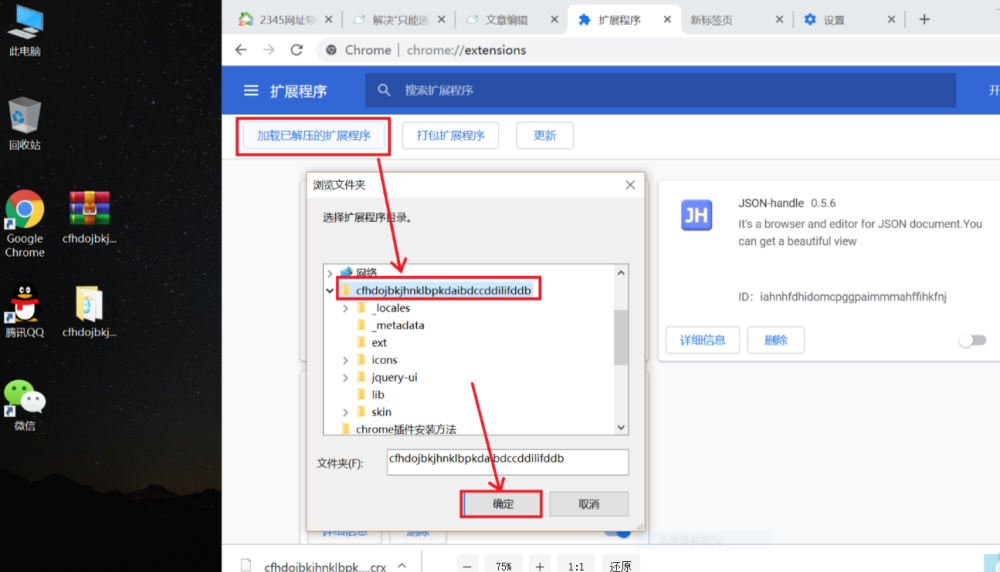
这样就安装成功了
友情提醒:
其他浏览器,包括qq浏览器,360浏览器,edge浏览器,猎豹浏览器,搜狗浏览器安装插件的方法都是类似的,以上内容大部分通用!















