




使用 OCR 引擎轻松从图像中提取文字!
图像阅读器 (OCR) 扩展可帮助您轻松地从任何图像中获取文字。它使用两种不同的开源 OCR 引擎。
第一个引擎称为 Tesseract。 Tesseract.js 是一个开源 Javascript 库,是通过用 C 和 C++ 编写的著名 Tesseract OCR 引擎的 Emscripten 端口制作的。请访问 (https://github.com/naptha/tesseract.js) 以获取更多信息。第二个引擎称为 Granite Dobling,由 IBM 开发 (https://huggingface.co/ibm-granite/granite-docling-258M)。请注意,当您选择 IBM Granite Dobling 时,该应用程序需要下载 AI 引擎的训练数据 (~1200MB)。因此,加载时请耐心等待。
要使用此插件,只需打开插件的界面并通过文件选择器(顶部部分)加载您的图像。在使用插件之前,请确保选择适当的 OCR 引擎和语言。对于 Tesseract,默认 OCR 语言设置为英语。对于 Granite Docling,您不需要设置语言;只需选择所需的后端(CPU 或 GPU)并等待应用程序完全加载。
注意:对于 Tesseract OCR 引擎,此插件使用“https://github.com/naptha/tessdata/tree/gh-pages/” GitHub 存储库来获取 OCR 操作所需的语言数据。对于 IBM Granite Dobling,它使用“https://huggingface.co/onnx-community/granite-docling-258M-ONNX”来获取 OCR 操作所需的训练数据。两种语言数据包都非常大,无法包含在插件包中。
要报告错误,请填写扩展程序主页 (https://mybrowseraddon.com/image-reader.html) 上的错误报告表。
Image Reader (OCR)插件谷歌浏览器安装教程
第一步:下载Image Reader (OCR)安装扩展
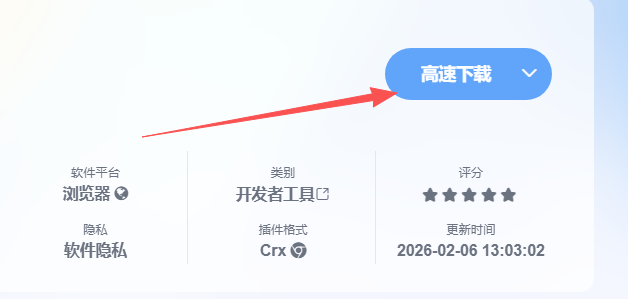
第二步:下载下来的扩展解压到你想放的文件夹里
比如我解压到extend文件夹

打开Chrome的扩展页面(chrome:// extensions /或按Chrome菜单图标>更多工具>扩展程序),右上角开发者模式,点击开启,蓝色为开启,灰色为关闭;
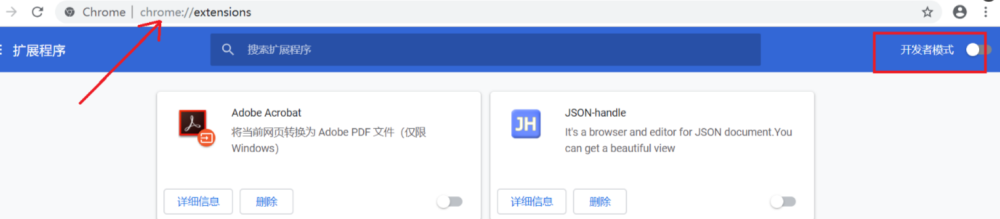
再次将crx文件拖放到扩展程序,页面左下角提示:“扩展功能、应用和主题背景可能会损害您的计算机。您确定要继续吗?”
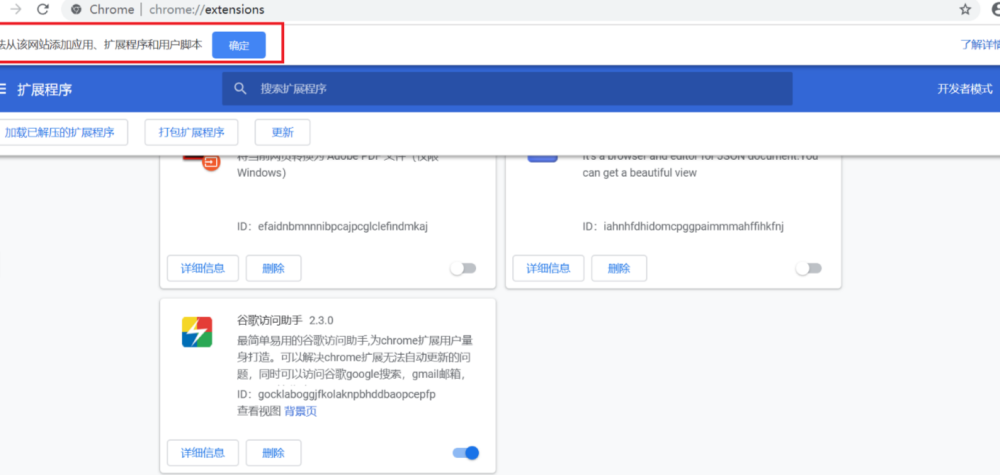
点击“继续”依然显示“无法从该网站添加应用、扩展程序和用户脚本”。尝试另一种办法方法。
第三步:把crx后缀改为zip,再进行解压
如果有些windows电脑系统查看不到文件扩展名,则可以通过以下设置:
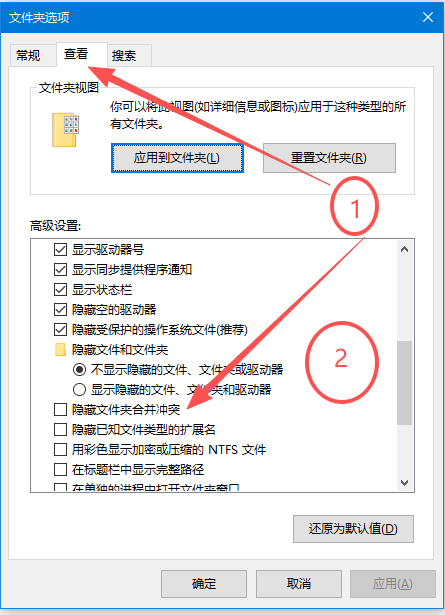
找到文件夹顶部,点击查看

点击查看,找到隐藏已知文件扩展名,去掉前面的勾即可
这样你就能看到解压好的扩展名:.crx
解压的扩展名为.crx
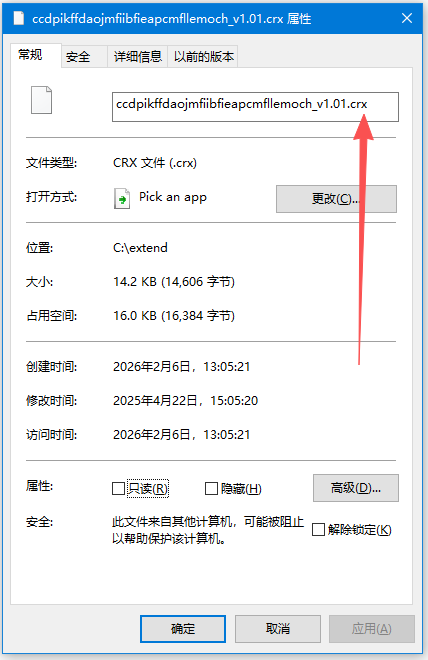
把.crx改为:zip
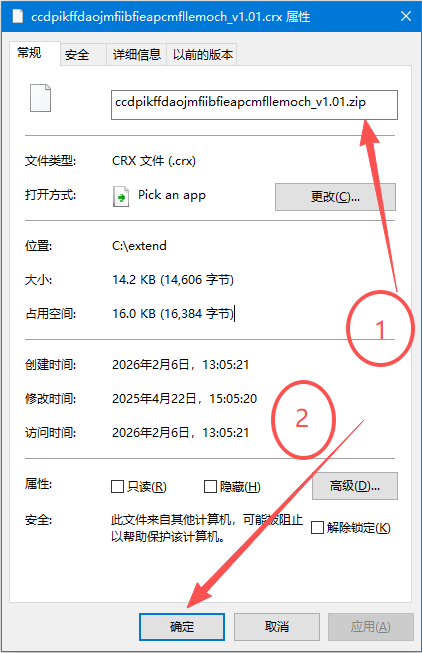
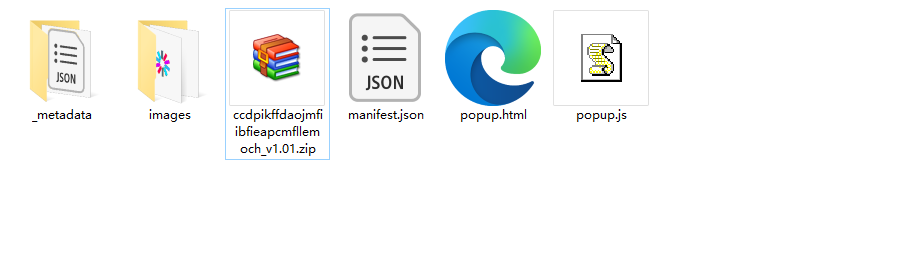
然后再用解压工具再解压一遍,即可得到扩展的全部文件
然后再谷歌浏览器插件页面选择:加载已解压的扩展程序
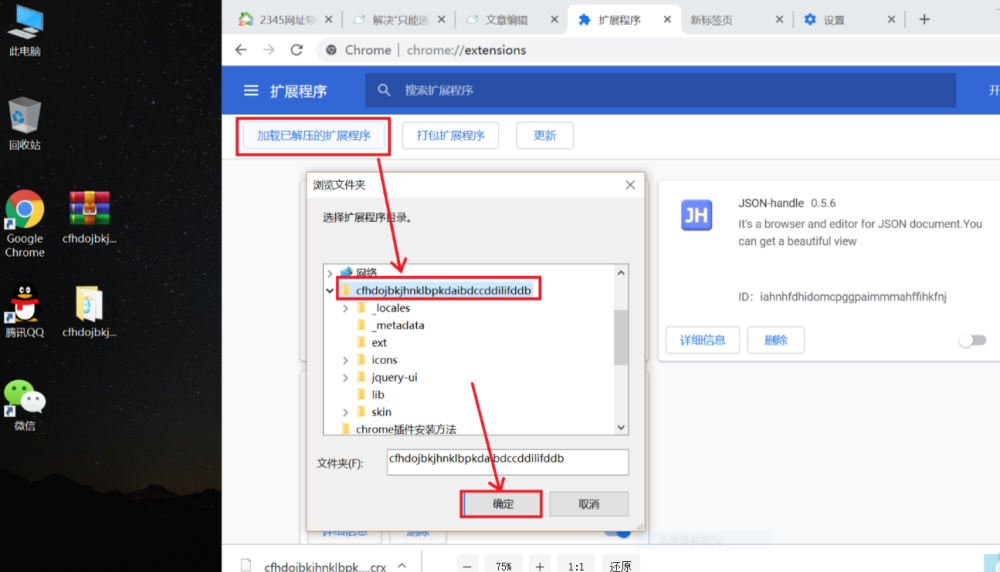
这样就安装成功了
友情提醒:
其他浏览器,包括qq浏览器,360浏览器,edge浏览器,猎豹浏览器,搜狗浏览器安装插件的方法都是类似的,以上内容大部分通用!















